FES-Forward Blog
Explore the Boundaries of Synthetic Biology with us. Stay up-to-date with the latest synthetic biology and DNA synthesis news, updates, and research.
Breaking Down Barriers in DNA Synthesis: Long Homopolymer DNA Sequences
SEP 17, 2024 │ 9 MIN READ
Synthesis solutions for DNA complexity, synthesizing homopolymeric sequences for poly(A) tails and more.

Long homopolymeric sequences, such as the poly(A) tails found in mRNA, are essential for the regulation and stability of genetic messages. Ensuring precise control over poly(A) tail length is crucial for optimizing mRNA-based therapeutics and other genetic technologies. Thus, providing DNA in vitro transcription templates with accurate homopolymer length, especially for long homopolymer stretches greater than 100nt, can present significant challenges in DNA synthesis. Furthermore, sequencing and other QC approaches to characterize homopolymer features, such poly(A) tail length, have their own intrinsic limitations, often leading to inaccuracies and inefficiencies in downstream applications. In this installment, we explore the complexities of long homopolymers, the critical role of poly(A) tails in mRNA, and the advanced techniques that are pushing the boundaries of what’s possible in synthetic biology.
What is a Long DNA Homopolymer?
A DNA homopolymer is a stretch of identical nucleotides over two bases in length (Figure 1). Current chemical synthesis companies recommend that customers limit homopolymers in their sequence submissions to stretches of < 10 As and Ts or < 6 Gs and Cs to avoid synthesis failures, while suggesting that sequences with longer homopolymers > 15-20 nt will be rejected completely during the ordering process.

Why are Long Homopolymers Challenging in DNA Synthesis?
Oligonucleotide synthesis of homopolymers using the chemical method causes low coupling efficiency, especially for purine (A and G) stretches (1). The result of series of poor coupling events causes low overall yield of the oligonucleotide and a final product that is difficult to purify, due to an abundance of truncated and single-base deletion sequences (2). When poly-d(A)-containing DNA transcription templates are produced in the lab, chemical synthesis lengths are limited by depurination from the acidic synthesis conditions, resulting in breaks in the DNA strand (2,3). Additionally, once oligonucleotides are synthesized, some homopolymers can lead to high molecular weight secondary structures that are challenging to denature, making downstream processing a challenge. For example, uninterrupted runs of G residues tend to form quadruplex or tetraplex strands that are stabilized by strong guanine-guanine interactions. These structures exhibit extreme thermal stability that make delivering a single stranded oligonucleotide difficult (4).
Homopolymer regions also create challenges in downstream applications, such as amplification and sequencing (5). Homopolymer templates are prone to polymerase slippage and stalling during replication and sequencing, further compounding errors. Slippage occurs when the primer and template strand misalign during polymerase extension, resulting in primer hybridization and extension at different positions along a homopolymer tract. This can cause insertion and deletion mutations (indels) leading to a range of homopolymer product lengths (6,7). An increased error rate for homopolymers has been found in both Illumina and Nanopore sequencers, where the output quality can become unreadable after > 10 repeating bases in some cases (7,8).
In PCR, indels occur at the highest frequency in homopolymers consisting of > 8 nt, as this is the number of bases that fit into the active site of Taq polymerase and many others (9,10). It is thought that when the active site is fully occupied by a homopolymeric sequence, it is more likely to dissociate and misalign (7). The presence of secondary structures from homopolymer repeats, such as the G quadruplex mentioned above, can also act as an arrest site during PCR that leads to truncated products (11).
What are Common Examples of Homopolymer DNA Sequences?
- The most recognized example of a homopolymer stretch is the messenger RNA poly(A) tail, a long stretch of adenosine nucleotides, whose length has been correlated to the efficiency of protein production or translation. Ensuring the correct poly(A) tail length is extremely important as it plays a role in multiple functions, such as:
- Control of mRNA turnover: long poly(A) tails of a defined length are stabilizing to the RNA and are gradually shortened throughout its life span. Once they reach a certain threshold, the shortened tails trigger mRNA degradation, thus acting as a timer for mRNA half-life (12).
- 3’ – 5’ RNA degradation: shorter poly(A) tails are added to promote degradation by the exosome (12).
- Regulation of translation and gene expression: poly(A) tails can lead to more efficient translation, with longer tails providing higher efficiency (12,13)
- Homopolymer stretches can be responsible for disease causing mutations in coding DNA, such as the 2184insA and 2184delA mutations in the poly(A) tract of the CFTR gene that lead to cystic fibrosis (14).
- Homopolymeric repeats of A/T are abundant in the plastid genome of plants and are considered valuable microsatellites for distinguishing different haplotypes between species (15).
- Stretches of G and C bases commonly form secondary structures that will be more thoroughly detailed in a future post on secondary structure complexities.
- G quadruplexes: early observations of guanine self-associations were found in oligonucleotides encoding Tetrahymena telomeres. The stable complexes discovered in the 3′-terminal overhang rendered the bases chemically inaccessible (16).
- Intercalated motifs (i-motif): C-rich regions are common in the human genome, where homopolymeric C runs can form intercalated duplexes held together by hemiprotonated cytosine-cytosine base pairs (17).
Fully Enzymatic Synthesis (FES) Enables Successful DNA Synthesis of Homopolymers
How can long oligos created with Fully Enzymatic Synthesis (FES) help build challenging homopolymer DNA sequences? Molecular Assemblies’ FES technology employs a template independent polymerase specifically engineered to overcome the challenges associated with synthesizing long runs of identical nucleotides, such as those found in mRNA poly(A) tails and G/C stretches that form strong secondary structures.
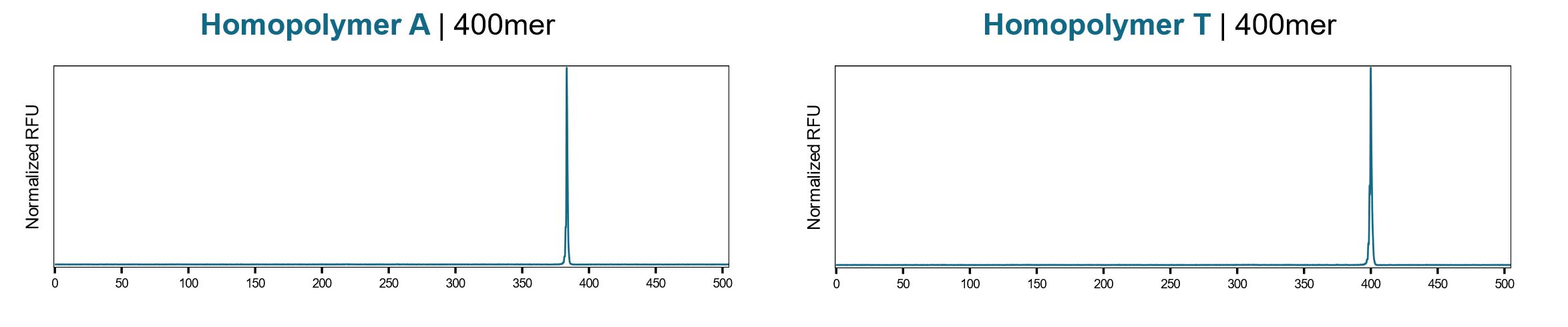
Our proprietary enzymatic synthesis process has a high cycle efficiency of 99.9% to allow long runs of stable poly(A) tails and operates at highly elevated temperatures to allow complex DNA to be prepared by melting secondary structure and. Figure 2 shows the synthesis of 400nt homopolymer A and homopolymer T stretch, each of which produces the target homopolymer length with high accuracy, and a sequence with 100% GC content prone to G quadruplex formation.
The ability to accurately synthesize long mRNA poly(A) tails using FES technology will enable important research using in vitro transcription (IVT) for many applications, including vaccine therapeutics. These applications first require building a linear DNA template containing a promoter for RNA polymerase binding and the sequence encoding the desired mRNA. This can be accomplished through traditional cloning of the sequence into a plasmid containing an upstream promoter, or by using oligonucleotides containing the T7 promoter for PCR or annealing to a complementary strand (18). The RNA polymerase then uses the DNA template to synthesize the RNA transcript, where the poly(A) tail has been observed as crucial for stability of the mRNA molecule (19,20). Longer poly(A) tails can lead to higher mRNA potency, although chemically synthesized oligonucleotides limit homopolymer stretches of A to < 10 as previously noted. Therefore, having the ability to synthesize sequences with poly(A) tails of any length, combined with high cycle efficiencies for synthesis of up to 400mer oligonucleotides, will now enable researchers to obtain templates for mRNA IVT without having to change potentially important regions due to homopolymer length restrictions.
To learn more about overcoming the challenges of synthesizing high DNA complexity, download our comprehensive white paper or see the first installments of this blog series on GC Content and Repetitive Sequences.
Explore More
Download the Complexity White Paper: Explore other complex DNA sequences by downloading our latest white paper on complexity.
Contact Us for More Information: Have questions or need more details? Reach out to our team for expert guidance on your DNA synthesis needs.
References
- Pirrung MC, Fallon L, Mcgall G. Proofing of Photolithographic DNA Synthesis with 3′,5′-Dimethoxybenzoinyloxycarbonyl-Protected Deoxynucleoside Phosphoramidites. 1998.
- LeProust EM, Peck BJ, Spirin K, McCuen HB, Moore B, Namsaraev E, et al. Synthesis of high-quality libraries of long (150mer) oligonucleotides by a novel depurination controlled process. Nucleic Acids Res. 2010 Mar 20;38(8):2522–40.
- Rink H, Liersch M, Sieber P, Märki W, Meyer F. A large fragment approach to gene synthesis. Nucleosides Nucleotides. 1985 Feb 1;4(1–2):269.
- Poon K, Macgregor RB. Unusual behavior exhibited by multistranded guanine-rich DNA complexes. Biopolymers: Original Research on Biomolecules. 1998;45(6):427–34.
- Xu C, Ma B, Gao Z, Dong X, Zhao C, Liu H. Electrochemical DNA synthesis and sequencing on a single electrode with scalability for integrated data storage [Internet]. Vol. 7, Sci. Adv. 2021. Available from: https://www.science.org
- Kunkel TA. DNA Replication Fidelity. Vol. 279, Journal of Biological Chemistry. 2004. p. 16895–8.
- Fazekas AJ, Steeves R, Newmaster SG. Improving sequencing quality from PCR products containing long mononucleotide repeats. Biotechniques. 2010 Apr;48(4):277–83.
- Laehnemann D, Borkhardt A, McHardy AC. Denoising DNA deep sequencing data-high-throughput sequencing errors and their correction. Brief Bioinform. 2016 Jan 1;17(1):154–79.
- Shinde D, Lai Y, Sun F, Arnheim N. Taq DNA polymerase slippage mutation rates measured by PCR and quasi-likelihood analysis: (CA/GT)n and (A/T)n microsatellites. Vol. 31, Nucleic Acids Research. 2003. p. 974–80.
- Hyun Eom S, Wang J, Steitz TA. LETTERS TO NATURE Structure of Taq polymerase with DNA at the polymerase active site. Vol. 304, Bucala, R. et a/. Proc. natn. Acad. Sci. U.S.A. 1989.
- Jensen MA, Fukushima M, Davis RW. DMSO and betaine greatly improve amplification of GC-rich constructs in de novo synthesis. PLoS One. 2010;5(6).
- Eckmann CR, Rammelt C, Wahle E. Control of poly(A) tail length. Wiley Interdiscip Rev RNA. 2011 May;2(3):348–61.
- Weill L, Belloc E, Bava FA, Méndez R. Translational control by changes in poly(A) tail length: Recycling mRNAs. Vol. 19, Nature Structural and Molecular Biology. 2012. p. 577–85.
- Makukh H, Křenková P, Tyrkus M, Bober L, HanČárová M, Hnateyko O, et al. A high frequency of the Cystic Fibrosis 2184insA mutation in Western Ukraine: Genotype-phenotype correlations, relevance for newborn screening and genetic testing. Journal of Cystic Fibrosis. 2010 Sep;9(5):371–5.
- Borsch T, Quandt D. Mutational dynamics and phylogenetic utility of noncoding chloroplast DNA. Plant Systematics and Evolution. 2009;282(3–4):169–99.
- Sundquist WI, Klug A. Telomeric DNA dimerizes by formation of guanine tetrads between hairpin loops. Letters to Nature. 1989;342:825–9.
- Assi HA, Garavís M, González C, Damha MJ. I-motif DNA: Structural features and significance to cell biology. Vol. 46, Nucleic Acids Research. Oxford University Press; 2018. p. 8038–56.
- Beckert B, Masquida B. Chapter 3: Synthesis of RNA by In Vitro Transcription. In: Methods in Molecular Biology: RNA Methods and Protocols [Internet]. 2016. p. 29–42. Available from: www.springer.com/series/7651
- Maruggi G, Zhang C, Li J, Ulmer JB, Yu D. mRNA as a Transformative Technology for Vaccine Development to Control Infectious Diseases. Vol. 27, Molecular Therapy. Cell Press; 2019. p. 757–72.
- Grier AE, Burleigh S, Sahni J, Clough CA, Cardot V, Choe DC, et al. Molecular Therapy-Nucleic Acids Producing Uniform mRNA From a Long Poly(A) Plasmid. Mol Ther Nucleic Acids [Internet]. 2016;5(e306). Available from: www.moleculartherapy.org/mtna

